Giới thiệu
Với một số cải tiến cho các mô hình CNN đầu tiên như AlexNet, VGG, … Dần dần đã có nhiều mô hình CNN mới được phát triển với khả năng học các đặc trưng tốt hơn. Nhưng nhà nghiên cứu đã phát triển các mô hình theo các hướng như mở rộng chiều sâu, chiều rộng của mô hình; tối ưu hóa chi phí tính toán. Trong phần này, mình sẽ giới thiệu một số hướng phát triển với các mô hình như InceptionNet v1-v3, ResNet, MobileNet.

Mô hình InceptionNet v1, v2, v3
Ý tưởng
Ý tưởng chính được đưa ra của nhóm tác giả GoogleNet (tên chính thức của mô hình trong ILSVRC) là phát triển mô hình không chỉ theo chiều sâu, mà còn là chiều rộng. Thay vì việc chúng ta phải cố định sử dụng một loại kernel size, InceptionNet tạo ra các module sử dụng nhiều Convolution với các loại kernel size khác nhau như 3x3, 5x5, 7x7, sau đó các đặc trưng sẽ được ghép nối với nhau.
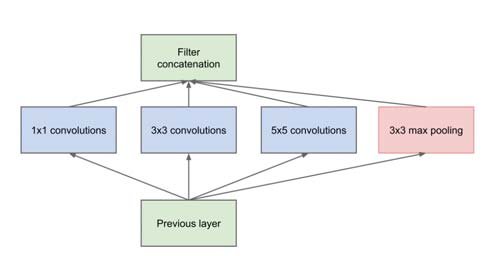
Việc này xuất phát từ ý tưởng từ việc học những phần khác nhau của bức ảnh với các vùng có kích thước khác nhau đòi hỏi ta cần có các kernel size chính xác, việc phối hợp nhiều loại kernel size giúp cho vùng nhận thức của mô hình rộng hơn. Tuy nhiên với việc dùng nhiều loại kernel như vậy sẽ làm tăng chi phí tính toán của mô hình, nhóm tác giả đã khắc phục vấn đề này bằng cách áp dụng convolution 1x1 trước khi đưa vào các loại kernel 3x3, 5x5; với mục tiêu làm giảm kích thước channel của feature map, từ đó giảm chi phí tính toán.
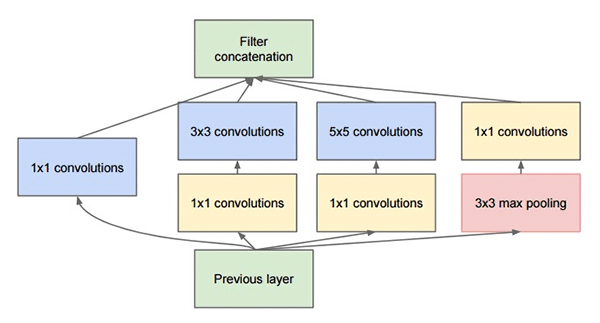
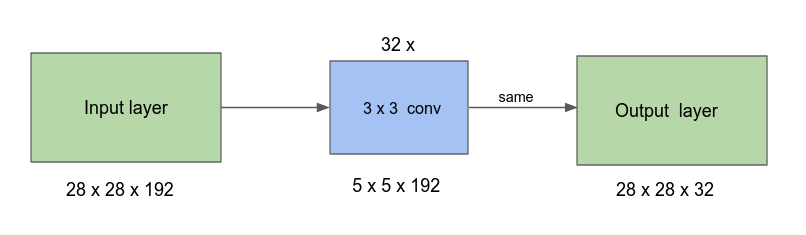
Về Convolution 1x1, đây là một phương pháp được lấy ra từ mô hình Network in Network. Vì sao gọi là Network in Network, vì khi tích chập 1 feature map WxHxC với Convolution 1x1 với N filter, tại mỗi vị trí trong WxH vị trí, ta đang tiến hành tạo ra 1 mô hình Perceptron 1 lớp kết hợp C giá trị thành 1 giá trị, và được scale up lại lên N lần tạo ra feature map mới kích thước WxHxN “cô đọng” lại từ WxHxC.
Mô hình Inception v1
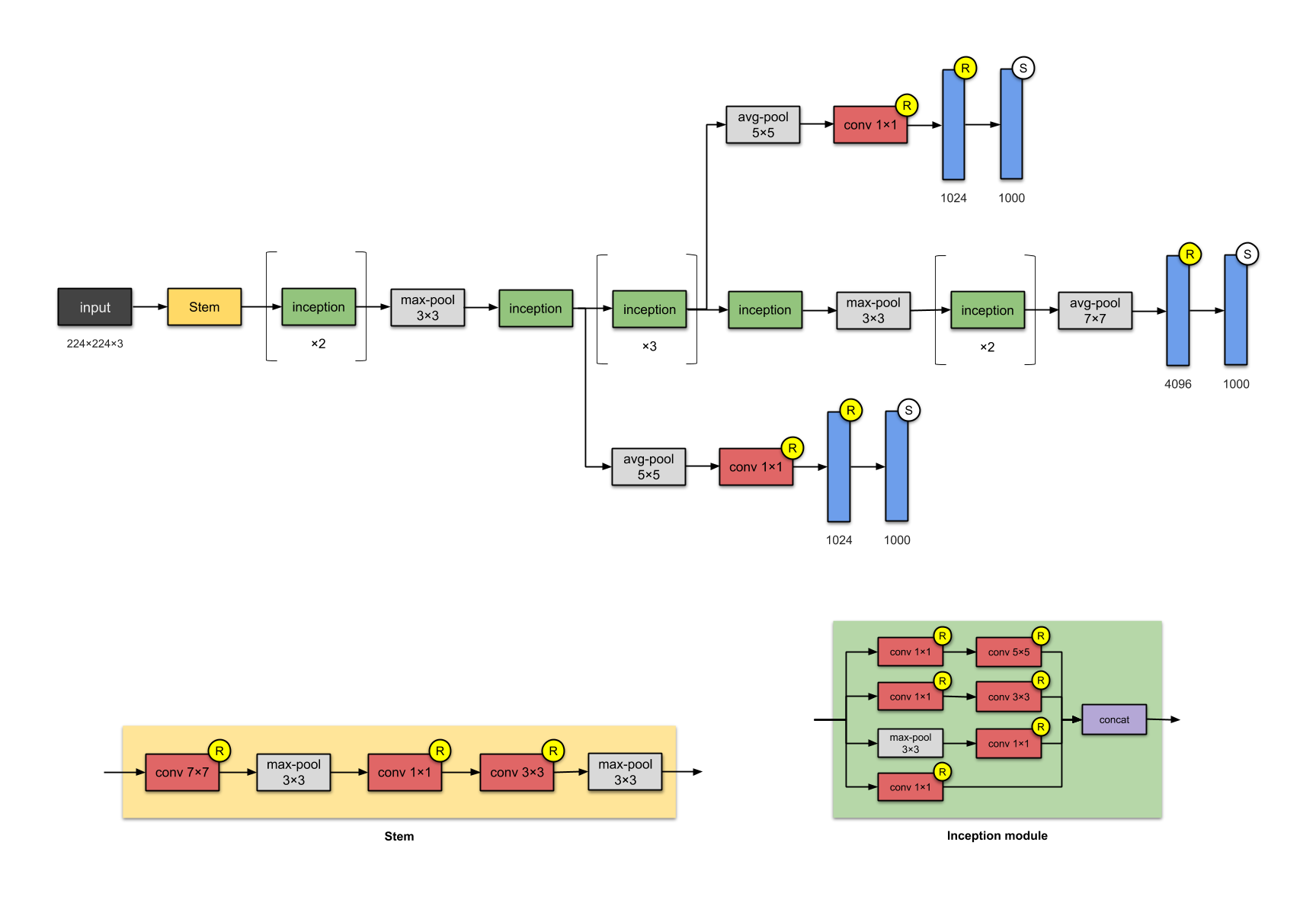
Một số tóm tắt về mô hình:
-
Mô hình bao gồm 22 lớp (nếu kể cả các lớp max-pooling là 27), nhưng thực tế số lớp được tính độc lập với nhau là 100 với các lớp Convolution được kết hợp trong các inception module.
-
Module đầu tiên trước khi đưa vào các Inception module là một Stem module với tuần tự 1 convolution 7x7, max pool 3x3, 1 convolution 1x1, 1 convolution 3x3 và max pool 3x3. Mục tiêu của lớp này không được tác giả giải thích, nhưng ta có thể hiểu là nhưng lớp ban đầu với các kernel size lớn và các vùng nhận thức lớn sẽ học tốt cho các đặc trưng cấp thấp như tần số, góc cạnh, …
-
Mô hình sử dụng một lớp Global Average Pooling 7x7 trước khi đưa nó vào các lớp FC. Các lớp FC của mô hình Inception nhìn chung khá ít để giảm các tham số và dồn hết các phần học đặc trưng vào các lớp Convolution.
-
Ngoài ra các phiên bản được cập nhật của Inceptionv1 cũng đã thêm vào 2 nhánh phụ Auxiliary Branch (được trích ra từ các lớp khác nhau) đóng góp cho quá trình huấn luyện nhằm giảm thiểu vấn đề vanishing gradient.
-
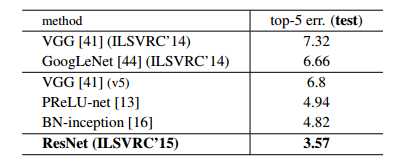
Kết quả khi so sánh với các mô hình trước trong ILSVRC. Mô hình InceptionNetv1 có độ lỗi nhỉnh hơn 0.6% so với VGG.
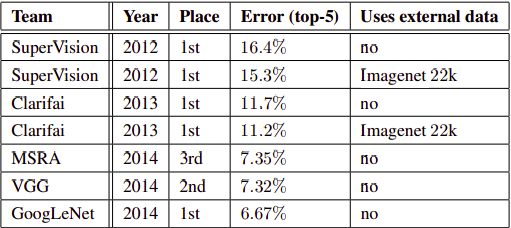
Mô hình Inception v2, v3
Mô hình Inception-v2 được đề cập trong bài báo Rethinking the Inception Architecture for Computer Vision đưa ra các phương pháp cải tiến cho mô hình v1. Và mô hình Inception-v3 chính là Inception-v2 với việc thêm vào BatchNorm.
Một số chỉnh sửa được đưa ra nhằm cải tiến để tối ưu các inception module:
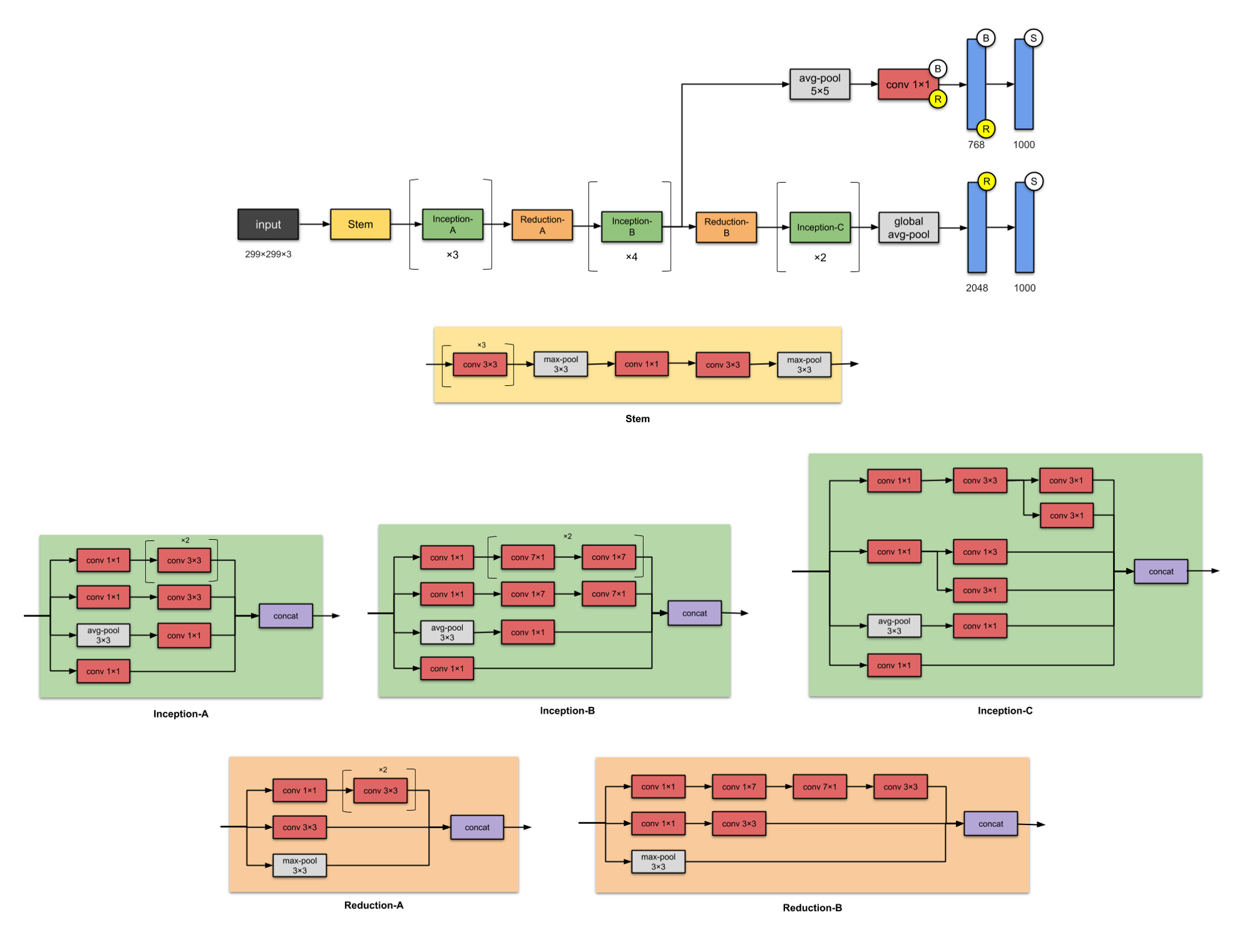
-
Thay thế convolution 7x7, 5x5 tương ứng thành 3 convolution 3x3 và 2 convolution 3x3, với tác dụng như VGG, giảm số tham số nhưng vẫn giữ nguyên vùng nhận thức 7x7 hay 5x5.
-
Biến đổi các convolution thành các Spatial Seperable Convolution để giảm thiểu tham số cho các convolution 3x3, 5x5, 7x7.
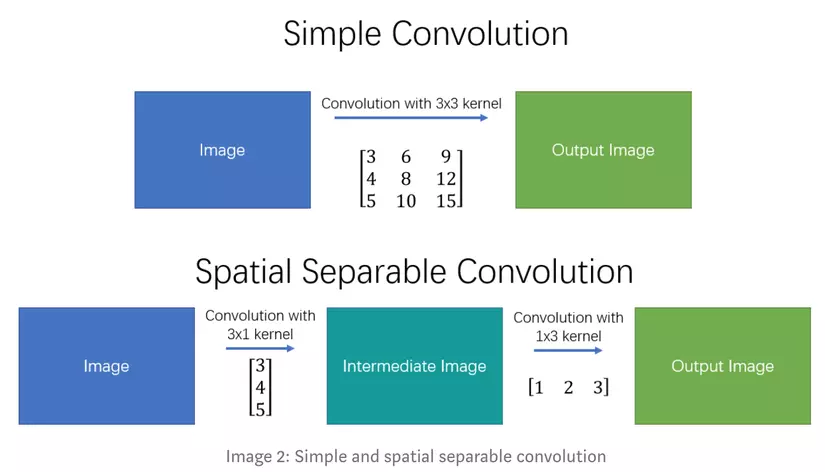
- Các thiết kế cho mạng học nhằm rộng hơn và cân bằng giữa chiều sâu và chiều rộng hơn so với mô hình v1. Ngoài ra, các mô hình sau còn thêm 1 số lớp Batch Normalization nhằm tăng tốc độ huấn luyện.
ResNet
Đây là một mạng học sâu cùng thời với InceptionNet, nhưng với những ý tưởng khác để phát triển chiều sâu của mạng học.
Vấn đề với các mạng Neuron
Kể từ khi một VGG ra đời, các mạng học sâu tiếp theo muốn được tăng thêm độ sâu càng nhiều càng tốt với kì vọng kích thước mô hình càng sâu sẽ càng có khả năng học tốt hơn, tuy nhiên sự thay đổi này không làm mạng tốt hơn, thậm chí còn tệ hơn rất nhiều so với những mạng có số lớp ít hơn.
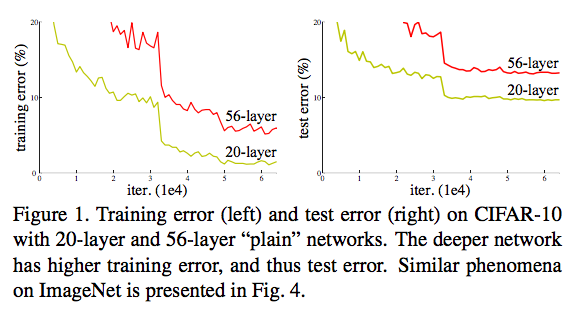
Để lý giải cho vấn đề này, tác giả của ResNet lập luận rằng việc ta thêm một số lớp vào một mạng học sâu “ít lớp” hơn, không thể nào làm giảm độ chính xác của mạng mới sau khi thêm được vói một giải pháp rất đơn giản: tái tạo mạng học mới bằng cách copy những lớp từ mạng học sâu “ít lớp” kia và thêm vào nhưng identity mapping. Tác giả chứng tỏ rằng việc tạo ra một mạng lớn hơn chắc chắn phải có “khả năng học” tốt hơn hoặc ít nhất là bằng so với mạng nhỏ hơn nó.
Skip connection và Residual Learning
Trong bài báo về ResNet, tác giả đưa ra lý giải cho những ván đề vì sao mạng học sâu hơn lại cho kết quả tệ hơn: mô hình quá khó để tối ưu và đạt được điểm tối ưu. Về sau này có một số bài báo khác có đưa ra các lý giải về việc gặp phải vanishing gradient của các mạng học sâu, cũng là một lí do cho việc học thất bại của các mô hình học sâu.
Để giải quyết vấn đề này, tác giả đưa ra một kiến trúc với tên gọi là Residual Network với kĩ thuật skip connection. Những skip connection có nhiệm vụ bỏ qua một vài lớp huấn luyện và kết nối thằng tới output. Kĩ thuật rất đơn giản như sau.
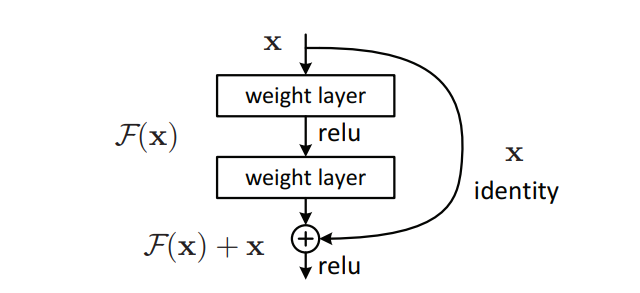
Kĩ thuật này thay đổi cách học của mạng học sâu, giả sử gọi hàm mục tiêu của ta cần học là H(x), trước đây ta sẽ dùng các mạng học để học từ x -> H(x). Bây giờ với skip connection, H(x) = F(x) + x, với F(x) là những đặc trưng mạng học được “bổ sung” vào x thay vì trực tiếp tác động vào x. Ta gọi đây là Residual Learning, F(x) là phần “residue” và x là “identity”.
Vì sao kĩ thuật skip connection lại hiệu quả ?
Đầu tiên, việc thay đổi mạng học thành những Residual Block ở trên khiến cho mạng học sâu của ta “dễ học hơn”, khi H(x) là một hàm kết hợp giữa 1 identity function I(x) = x và 1 phần “residue” F(x). Giả sử, trong quá trình tối ưu, việc tối ưu hàm F(x) không cải thiện cho hàm mục tiêu H(x) (thậm chí là làm tệ đi), bài toán tối ưu đơn giản sẽ zero out F(x) và vẫn lưu giữ lại H(x) = 0 + I(x), giúp cho mô hình học được các identity mapping và tránh bị hiện tượng degrade như đã nói.
Thứ 2 là vẫn đề về độ phức tạp của mô hình, việc thêm nhiều lớp vào mạng học sâu chắc chắn sẽ khiến cho khả năng học mô hình tăng lên, tuy nhiên không có gì đảm bảo được rằng ta có thể dễ dàng tìm kiếm được optimal solution hơn so với mô hình nhỏ hơn (thường là sẽ khó hơn rất nhiều).

Một cách mô hình hóa cho các cấu trúc mạng là thành những lớp không gian mô hình F1, F2, F3 … với các kích thước F sau sẽ lớn hơn; và hàm chứa optimal solution ta cần là f’.
Với một mô hình F bất kì, ta tạo ra một mô hình lớn hơn là F’, nếu $F \not\subseteq F’$, nghĩa là các F’ lớn hơn không bao lấy các mô hình nhỏ hơn thì không có gì đảm bảo F’ này sẽ tới gần hơn tới optimal solution f’, thậm chí có thể tệ hơn nhiều. Vói sự thay đổi của skip connection và Residual Learning, ta có thể chắc rằng các mô hình lớn hơn được vẫn giữ được sự hiệu quả của mô hình nhỏ, và hoàn toàn thực sự có khả năng học “mạnh” hơn.
Một số phân tích thêm về sự hiệu quả của kĩ thuật skip connection trong các mạng học sâu các bạn có thể xem thêm tại đây từ BKAI
Mô hình ResNet và kết quả thực nghiệm
Các thực nghiệm đầu tiên của ResNet về sự hiệu quả của việc sử dụng skip connection bằng việc so sánh giữa mô hình 34 lớp không có skip connection và 34 lớp có skip connection như sau.
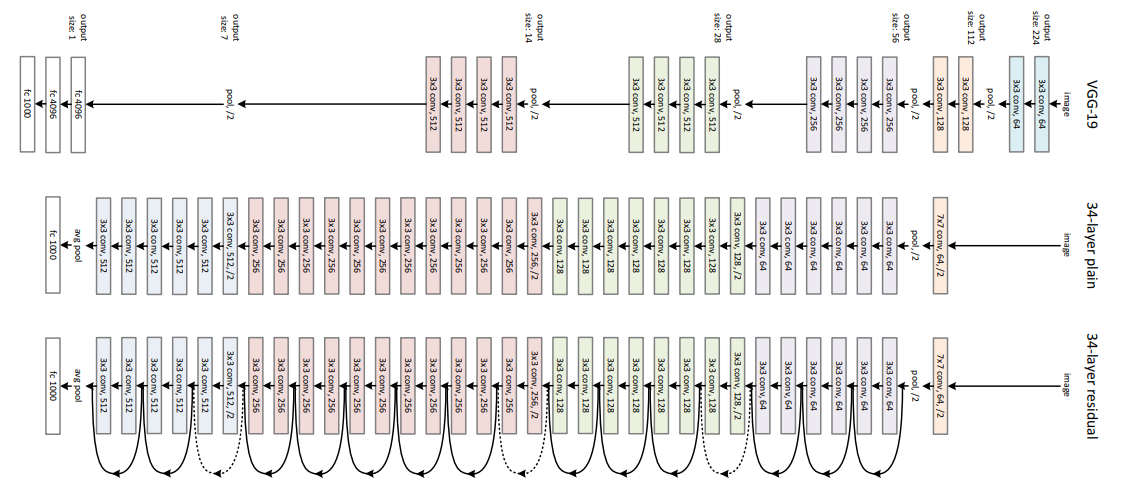
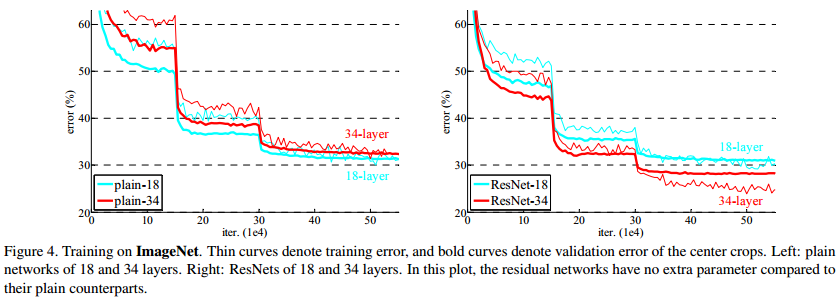
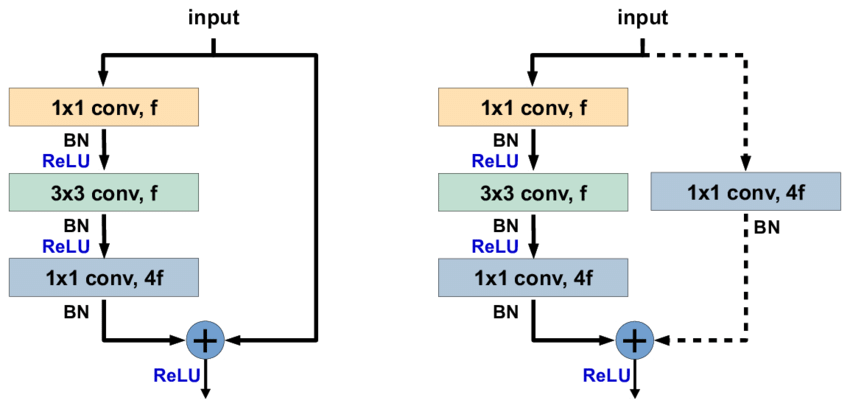
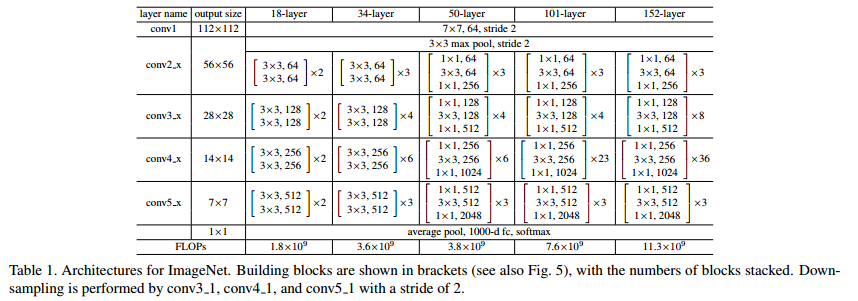
Mô hình ResNet được xây dựng dựa trên 2 module cơ bản là basic block cho các cấu hình mô hình nhỏ như ResNet-18 và ResNet-34; và bottleneck block để xây dựng cho các mô hình sâu hơn như ResNet-50, ResNet-101, ResNet-152.
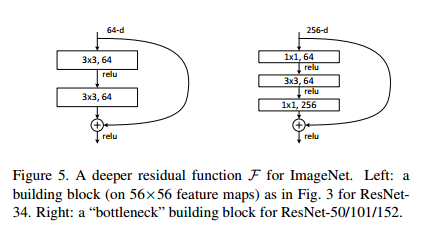
Nói kĩ hơn về các thành phần cơ bản của ResNet:
-
Với basic block là 2 convolution 3x3 nối với nhau cho phần residual learning.
-
Với bottleneck block là 3 convolution liên tiếp nhau bao gồm 1 convolution 1x1 để giảm số chiều sâu của đặc trưng, 1 convolution 3x3, 1 convolution 1x1 để tăng số chiều sâu lên đúng với đầu vào ban đầu. Lí do gọi đây là bottleneck (cổ chai) vì kiến trúc này khi đưa vào sẽ làm nhỏ chiều sâu đặc trưng sau đó mới học và tăng lên lại đúng với số chiều ban đầu, tác giả đã tận dụng khả năng thay đổi chiều của các convolution 1x1 để giảm chi phí tính toán cho loại block này.
-
Ở các block nếu gặp trường hợp không đúng chiều, tác giả sử dụng các convolution 1x1 để điều chỉnh lại cho skip connection. Và sau mỗi convolution, tác giả đi kèm với 1 lớp batchnorm trước khi đưa vào hàm kích hoạt ReLU.
Mô hình ResNet được đề xuất đã tạo nên một mô hình cực sâu với 152 lớp, so với VGG-19 hay Inception với 22 lớp. Mọi người có thể tự tham khảo lại source code cho ResNet ở mọi cấu hình tại đây
Kết quả so với các mô hình trong cuộc thi ILSVRC đã vượt trội hơn so với Inception và VGG.
MobileNet
Trong phần này mình muốn đưa ra một mô hình tuy không phải là SOTA nhưng cực kì quan trọng vì nó phù hợp với các thiết bị đòi hỏi chi phí tính toán, lưu trữ thấp như điện thoại, thiết bị nhúng, chỉ với những tinh chỉnh phù hợp.
Mục tiêu chính được đề ra trong mô hình MobileNet là:
-
Làm giảm số lượng tham số trong mô hình
-
Làm giảm chi phí tính toán thông qua đại lượng được đưa ra là Multi-Adds (Multiplications and Additions - số lượng phép tính cộng và nhân).
Ý tưởng
Xuất phát từ việc giảm chi phí tính toán từ việc phân tách các phép convolution nxn thành 2 convolution nx1 và 1xnnhư trong các mô hình Inception.
Với việc thay đổi từ phép convolution tiêu chuẩn thành các seperable convolution ta có thể giảm chi phí tính toán từ n phép nhân (từ convolution nxn) thành 2n phép nhân (cho spatial seperable convolution)
MobileNet đã giới thiệu 1 loại convolution mới nhằm thay thế cho các phép convolution tiêu chuẩn trước đây, được gọi là Seperable Depthwise Convolution, với sự rút gọn về chi phi tính toán và số lượng tham số. Seperable Depthwise Convolution bao gồm 2 convolution khác nhau:
- Depth-wise convolution: Đây là một loại Convolution đặc biệt, khi nào bao gồm M filter với kích thước KxK nhưng mỗi filter áp dụng cho riêng 1 chiều sâu m trong M chiều của feature-map ban đầu. Mục tiêu sử dụng convolution này là học được những feature riêng lẻ của từng độ sâu (chưa có kết hợp giữa các độ sâu với nhau).
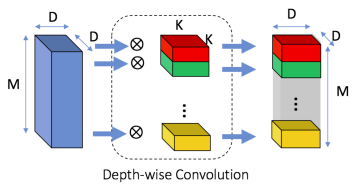
- Point-wise convolution: Đây chính là các convolution 1x1 được áp dụng giống như trong mô hình Inception, mục tiêu của Pointwise Convolution là kết hợp các đặc trưng từ nhiều vị trí của các độ sâu cũng như là điều chỉnh lại độ sâu
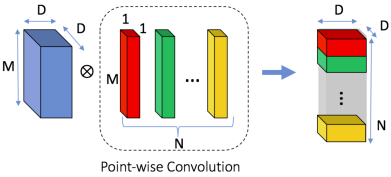
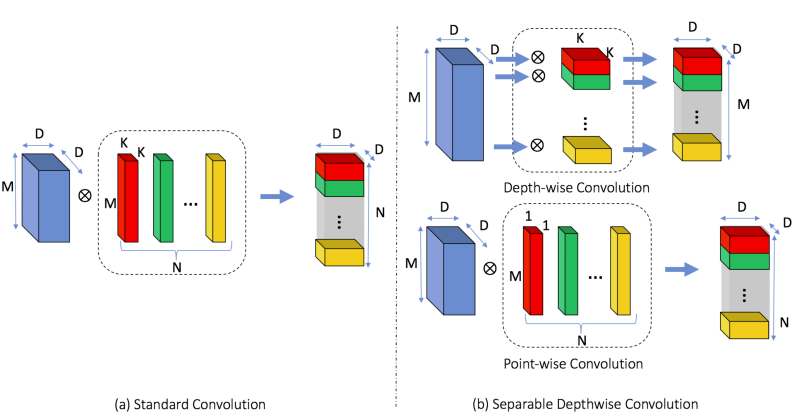
Với chi phí tính toán được giảm bởi việc thay thế các convolution tiêu chuẩn bằng các Depthwise Seperable Convolution ta đã giảm được chi phí tính toán cũng như số lượng tham số như sau:
- Về chi phí tính toán: Theo hình, chi phí cho các convolution tiêu chuẩn là M x D x D x N x K x K. Với Depthwise Seprable Convolution là D x D x M x K x K + D x D x M x N. Xét theo tỉ lệ:
- Về số lượng tham số: Số lượng tham số của convolution tiêu chuẩn là M x K x K x N. Số lượng tham số của Depthwise Seperable Convolution đã được giảm còn M x K x K + M x N
Mô hình MobileNet và kết quả thực nghiệm
Mô hình MobileNet
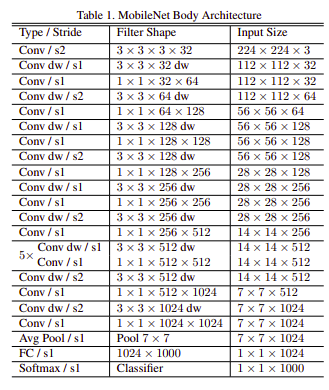
Mô hình MobileNet được Google giới thiệu vào năm 2017 với 30 lớp có một số điểm đáng chú ý sau:
-
Lớp đầu tiên Conv / s2 3x3x3x32 là Convolution tiêu chuẩn 3x3, stride 2, 32 filter.
-
Các lớp Conv dw/s1 hay là Conv dw/s2 là các Depth-wise Convolution stride bằng 1 hoặc 2.
-
Các lớp Conv / s1 1x1 là các Convolution 1x1 được đặt tên là Point-wise Convolution.
-
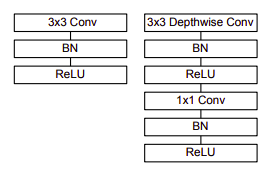
Các module của MobileNet đều sử dụng Batch Normlization trước khi đưa qua hàm kích hoạt ReLU.
- Trước khi đưa vào đưa vào lớp FC 1000 unit để phân lớp, feature map được đưa qua một Avg Pool s1 là một Global Average Pooling để đưa feature map 7x7x1024 thành 1x1x1024.
Source code của MobileNet mọi người có thể tham khảo tại đây
Các kết quả thực nghiệm và cấu hình
Đầu tiên về sự so sánh giữa mô hình MobileNet với các Convolution tiêu chuẩn so với sử dụng các Depthwise Seperable Convolution.

MobileNet với Depthwise Seperable Convolution tuy thấp hơn 1% so với các Convolution tiêu chuẩn, nhưng mô hình đã giảm nhẹ đi tới 90% lượng tham số và số phép tính.
Nhóm tác giả của MobileNet đã tạo ra các cấu hình khác nhau bằng các siêu tham số để làm nhẹ hơn các mô hình theo 2 dạng tham số:
- Sử dụng tham số alpha = {0.25, 0.5, 0.75, 1} là một tham số để điều khiển các tất cả các chiều sâu của feature map ở các lớp.
Với alpha = 1.0 là baseline model cho MobileNet lớn nhất.
Chi phí tính toán khi học từ chiều sâu M thành N sẽ được scale lại thành (alpha * M) -> (alpha * N), chi phí đó sẽ thành: D x D x (alpha x M) x K x K + D x D x (alpha x M) x (alpha x N).
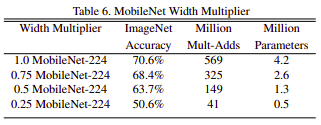
- Sử dụng tham số rho trong khoảng [0.0, 1.0] để kiểm soát các độ phân giải của ảnh đầu vào.
Gọi D là ảnh đầu kích thước ảnh đầu vào, scale lại từ D là (rho x D) có chi phí là: (rho x D) x (rho x D) x (alpha x M) x K x K + (rho x D) x (rho x D) x (alpha x M) x (alpha x N).
Trong bài báo MobileNet các (rho x D) được thực nghiệm cho các kích thước khác nhau là rho x D = {224, 192, 160, 128}.
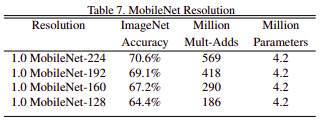
Nhìn chung chúng ta có rất nhiều sự lựa chọn về cấu hình cho MobileNet khác nhau để phù hợp cho việc đưa mô hình này lên các thiết bị khác nhau.
Sau khi đưa ra các cấu hình khác nhau cho MobileNet, nhóm tác giả đưa ra các kết quả của MobileNet so với các SOTA với tập ImageNet và tập Standford Dogs.
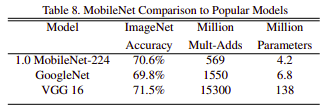
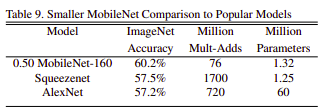
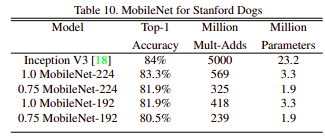
Nhận xét trên các tập dữ liệu các mô hình MobileNet có kết quả tương đối cao, gần với các SOTA lúc đó, nhưng có số lượng tham số cũng như chi phí tính toán thấp hơn rất nhiều.
MobileNetv2
Đây là mô hình cải tiến MobileNet được Google đưa ra với một số cải tiến đáng chú ý sau:
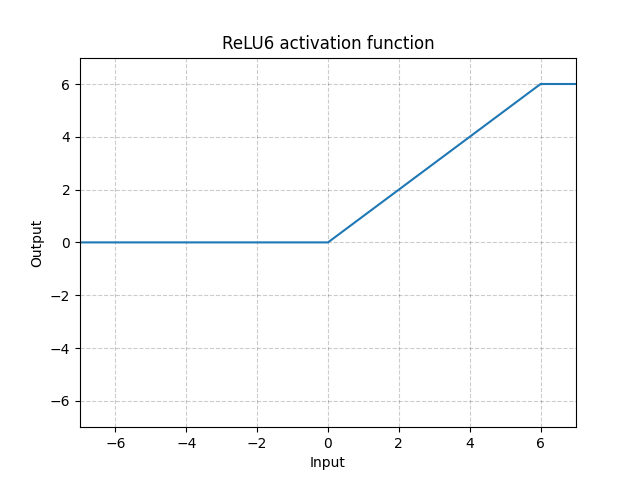
- Sử dụng hàm kích hoạt ReLU6(x) = min(max(0, x), 6), và sau này các phiên bản cập nhật của MobileNet cũng sử dụng. Có một số bài báo đã chứng minh việc sử dụng hàm này tốt hơn so với ReLU.
- Giới thiệu Inverted Residual Block, nhóm tác giả giới thiệu ra một loại bottleneck module áp dụng skip connection (tương tự như ResNet) và áp dụng hàm kích hoạt TUYẾN TÍNH thay cho các hàm kích hoạt phi tuyến.
Inverted Residual Block
Trong blog tóm tắt về MobileNetV2 được Google công bố tại đây và bài báo MobileNetV2: Inverted Residuals and Linear Bottlenecks, nhóm tác giả đã giới thiệu một module gọi là Inverted Residual Block.
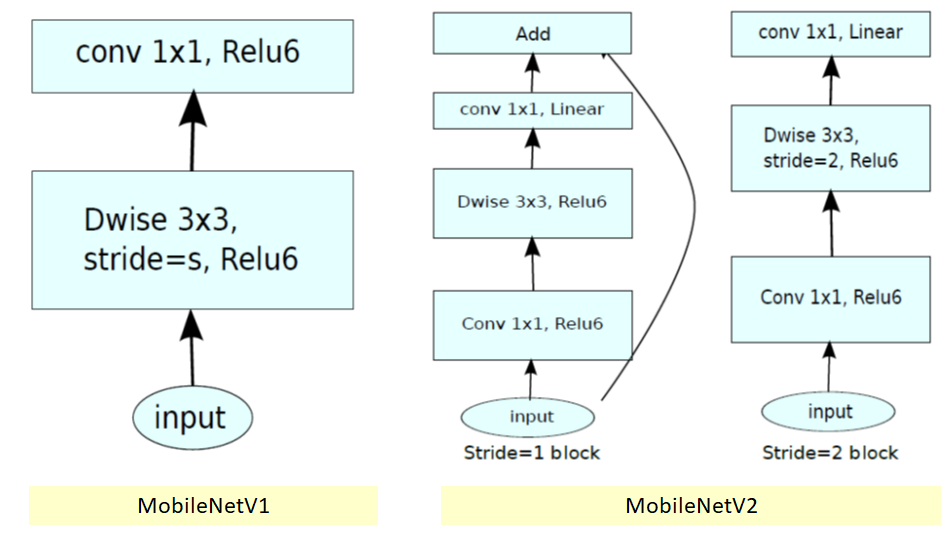
MobileNetV2 giới thiệu 2 loại module tương ứng với từng stride như sau:
-
Với module stride 1, trước khi đưa vào một Depth-wise Convolution 3x3 stride 1, ngươi ta sử dụng thêm một 1x1 Convolutionvới hàm kích hoạt ReLU6, và trước khi đưa ra output cũng sử dụng một 1x1 Convolution với hàm kích hoạt là tuyến tính. Ngoài ra module này sử dụng skip connection tương tự như ResNet.
-
Với module stride 2, chỉ khác với module stride 1 là ta sử dụng Depth-wise Convolution 3x3 stride 2, và không sử dụng skip connection.
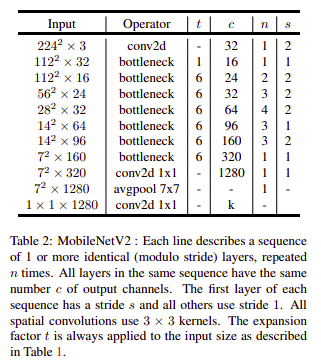
Với sự thiết kế cả 2 module này, người ta đều gọi chúng là những bottleneck module. Chúng được định nghĩa chung qua bảng sau:
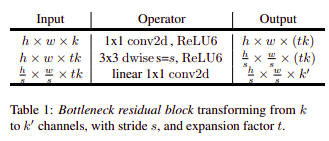
Giải thích về các bottleneck này được áp dụng cho cả 2 module stride 1 và stride 2, tuy nhiên chỉ khác biệt với tham số t, ở trong mô hình MobileNetV2 tham số t này thường là 6. Nếu tham số t càng lớn nghĩa là số chiều của convolution 1x1 đầu tiên sẽ càng cao.
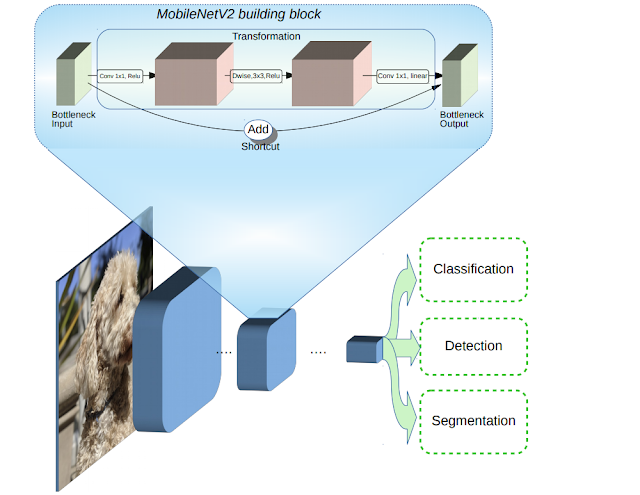
Lấy ý tưởng từ Residual Block trong ResNet, bottleneck của ResNet sẽ làm giảm chiều độ sâu bằng các 1x1 convolution trước (đã được giới thiệu ở ResNet), cụ thể là chiều input và output sẽ lớn hơn so với chiều trung gian.
Ngược lại với loại Residual Block này, tác giả của MobileNetV2 lại muốn làm tăng chiều độ sâu trước khi học các đặc trưng (nên gọi là “Inverted” - ngược), chiều của input và output sẽ nhỏ hơn và từ đó có thể đẩy khả năng bottleneck này học được nhiều đặc trưng hơn.
Thực nghiệm về hàm kích hoạt và skip connection
Bài báo cũng đưa ra một số thực nghiệm bằng việc thay thế hàm kích hoạt của đầu ra các bottleneck là Tuyến tính, hay việc sử dụng các skip connection.
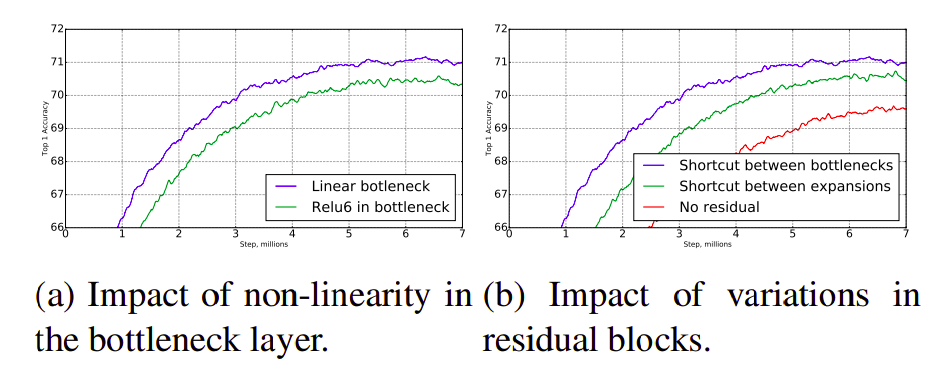
Qua thực nghiệm thì việc sử dụng hàm tuyến tính cho các bottleneck và việc sử dụng skip connection cho ra kết quả cải thiện rất đáng kể, đây có thể là những use case sau này cho việc thiết kế các module của các mạng học sâu mà mọi người có thể tham khảo.
Kết quả thực nghiệm mô hình
Qua đây một số kết quả thực nghiệm của mô hình MobileNetV2 so sánh với các mô hình cùng kích thước được đưa ra.
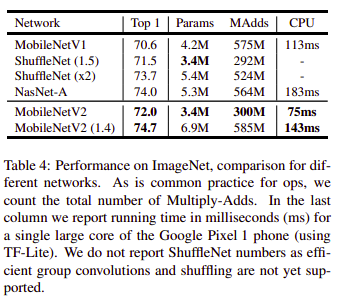
Nhìn chung mô hình MobileNetV2 có kết quả vượt qua mô hình MobileNetV1 về cả độ chính xác, số lượng tham số, số lượng phép tính và tốc độ tính toán và thậm chí gần đạt tới khả năng các mô hình SOTA (tuy nhiên vẫn chưa thể vượt qua).
Với các mô hình cùng kích thước về lượng tham số như ShuffleNet 1.5, mô hình MobileNetV2 nhỉnh hơn, và mô hình scale up với các kích thước alpha như mình đã đề cập của MobileNet là 1.4 cho ra kết quả tốt hơn.
Tổng kết
Sau khi điểm qua các kĩ thuật của các mô hình như Inception, ResNet, MobileNet chúng ta có thể áp dụng 1 số use case như sau:
-
Sử dụng nhiều loại kernel khác nhau, có thể bắt chước như InceptionNet sử dụng các kernel lớn nhất 7x7 ở đầu, và phối hợp các kernel 3x3, 5x5 cho các module khác nhau.
-
Các kĩ thuật làm giảm độ phức tạp tính toán: với InceptionNet là Spatial Seperable Convolutions phân tách các convolution nxn thành nx1 và 1xn; với MobileNet có thể sử dụng Depthwise Seperable Convolution.
-
Skip connection cho các mạng học sâu rất tốt, có thể khắc phục các vấn đề như vanishing gradient, degrade problem khi thiết kế các mô hình học sâu. Sau này mô hình ResNet có áp dụng tương đối nhiều ý tưởng từ Inception và MobileNet để tạo ra ResNeXt hay Wide-ResNet.
-
Một số kĩ thuật có thể dùng để tăng tốc độ học như Batch Normalization hay là sử dụng Auxiliary Branch để khắc phục overfitting cho mô hình như InceptionNet.
-
Thiết kế các bottleneck module để học các đặc trưng hiệu quả hơn.
-
Với các mô hình học để triển khai trên các thiết bị nhỏ như di động, thiết bị nhúng, có thể chọn các mô hình như MobileNet, hoặc SqueezeNet, ShuffleNet với các kĩ thuật làm giảm chi phí tính toán.



Leave a comment