Mô hình Vistral-V, Visual Instruction Tuning với Vistral - mô hình Vision-Language cho tiếng Việt
Mở đầu
Sau khi hoàn thành dự án đầu tiên về Vista và đón nhận được sự đánh giá tương đối từ cộng đồng, đã có một vài người sử dụng qua bộ dữ liệu, à tất nhiên là cả sự PR của các anh em VietAI. Tụi mình tiếp tục huấn luyện mô hình.
Lần này, bên VietAI có hỗ trợ compute, cụ thể là truy cập vào 1 con GPU A100 trong 1 tháng. Bọn mình thấy đây là cơ hội để thử nghiệm với dữ liệu, cũng như một số hypothesis về mô hình nên đã quyết định làm tiếp.
Mô hình
Tụi mình thay thế một vài phần của LLaVA cho huấn luyện để phù hợp hơn với tiếng Việt:
-
Backbone LM: tụi mình sử dụng Vistral vì mình thấy đây là mô hình tiếng Việt mình tin cậy nhất (và cũng từ một bạn giáo viên trong VietAI).
-
Backbone Vision: mình có tìm hiểu và thấy nên sử dụng SigLIP, nhìn chung đa số các mô hình mới đều sử dụng nó. Mình đề xuất sử dụng SigLIP-multilingual để có thể dễ match hơn với tiếng Việt.

Ngoài ra về cách sử dụng dữ liệu, chúng mình cũng có nhiều cân nhắc thay đổi để nó work với tiếng Việt và sẽ được bàn luận ở phần tiếp.
Phương pháp
Version 1
Ban đầu phương pháp tụi mình sử dụng sẽ lấy từ mô hình LLaVA, đúng tụi mình đã customize codebase của LLaVA và tiến hành thử nghiệm.
Ban đầu sẽ là bước pretrain (hay LLaVA gọi là feature alignment), tụi mình sử dụng data của ShareGPT. Để học phần projector nối Vision Encoder với Language model.
Kết quả từ lúc đầu không quá tốt khi mà loss curve không giảm và có dấu hiệu overshoot qua các điểm tối ưu. Lúc này mình phát hiện ra một thứ là phải scale lại learning rate dựa vào batch size để làm learning rate nhỏ hơn, hạn chế vấn đề này.
Tụi mình lấy số learning rate và số GPU (dựa vào để tính batch size) của LLaVA gốc để làm chuẩn và scale theo số lượng device hiện có, và kết quả tương đối tốt khi giai đoạn pretrain đã có loss curve đẹp hơn.
Tiếp theo, sau feature alignment là phần instruction finetuning, ở đây tụi mình sử dụng toàn bộ data là tương ứng với 3 subset LLaVA conversation, detail description, complex reasoning. Ở giai đoạn này là giúp model học cách trả lời theo instruction và prompt.
Kết quả thử nghiệm giai đoạn đầu cũng tương đối khả quan, model có thể trả lời được một vài câu hỏi đơn giản.
Version 2
Version 2 là version tụi mình thử nghiệm cho thêm data WIT vào trong pretrain vì tụi mình đánh giá kết quả pretrain vẫn chưa quá tốt.
Thực tế tụi mình giữ nguyên các thử nghiệm, thêm data và loss curve cho giai đoạn sau đã cho kết quả tốt hơn rất nhiều.
Kết quả khi chạy thử nghiệm cũng cho thấy khi thêm dữ liệu WIT, model trả lời được thêm nhiều tri thức mới hơn (có lẽ từ WIT) và cách trả lời chi tiết hơn.
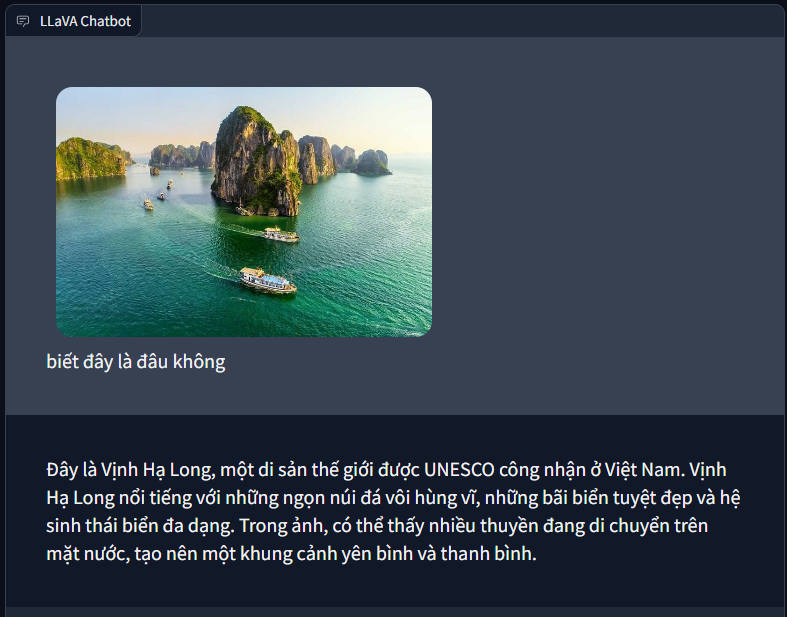
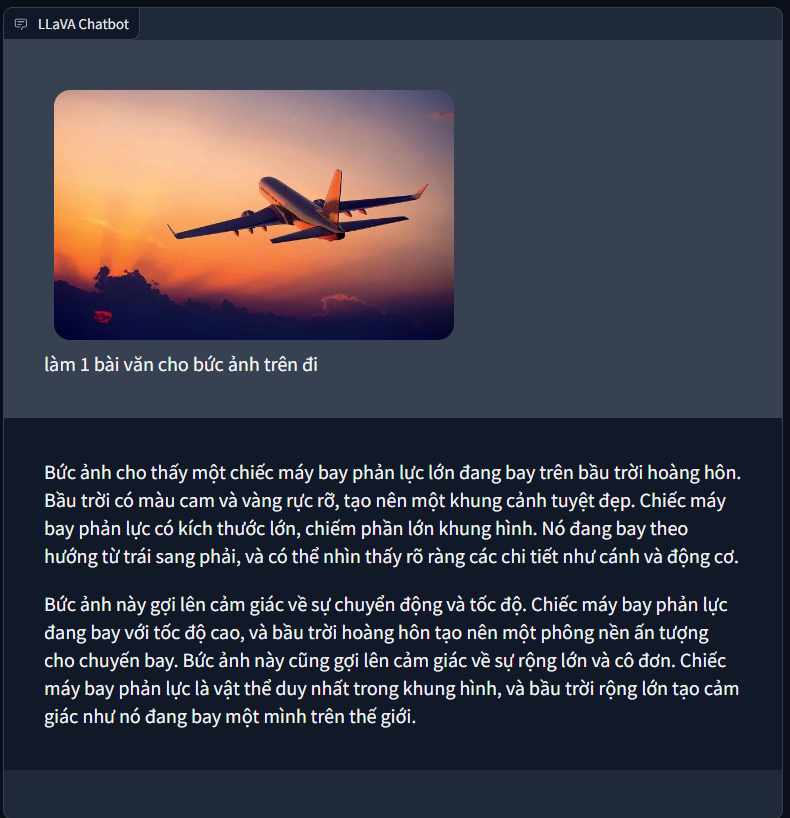
Release
Thật ra tụi mình chỉ muốn release như là một thành quả cho suốt quá trình, và cũng vì một phần mọi người cũng đang khá bận trong nhiều thời điểm. Có thể giai đoạn này cần thêm một vài evaluation, cũng như có đánh giá với các mô hình hiện tại. Nhưng tụi mình đã cảm thấy đủ cho một side project cơ bản, chứng minh được mọi hypothesis và kết quả khá khả quan.
Mình hơi bất ngờ là mô hình khi tung ra lại không được nhiều người đón nhận bằng dữ liệu =)) Có vẻ là mô hình còn cùi và cần nhiều thứ cải thiện hơn, nhưng đó có thể cho tương lai, với hiện tại đã tạm ổn.
Trong tương lai không biết sẽ làm tiếp những gì, nhưng đây là một dự án khá mĩ mãn đối với mình.



Leave a comment